



.jpg)
AI systems now influence crucial decisions in healthcare, finance, hiring, and many other areas. When you build AI applications, you face two critical challenges: protecting user privacy and preventing unfair bias.
These issues affect everyone from small startups to large enterprises, and solving them makes your AI solutions more effective and trustworthy.
You might wonder why these problems persist despite advances in AI technology. The answer is how we collect data, train models, and deploy systems without adequate safeguards. Many companies learn this lesson the hard way, through public failures that harm users and damage reputations.
In this blog, we'll go through practical approaches to building AI systems that respect privacy and treat all users fairly. You'll learn to identify bias in both traditional and generative AI, implement privacy protection techniques, and use effective tools for creating better AI solutions.
What Is Bias in Traditional ML Systems
Bias in AI occurs when systems consistently produce unfair results for certain groups. You might think sophisticated algorithms would avoid human prejudices, but they learn from historical data that often contains existing biases.
Consider what happened with Amazon's recruitment AI. The company built a system to streamline hiring, but discovered it was systematically disadvantaging women, especially for technical positions. The system was trained on historical hiring data that reflected the male-dominated tech industry. Despite their efforts to fix the problem, Amazon eventually abandoned the project when they realised they couldn't fully eliminate these biases.
Let's look at a specific example of how this bias manifested. The AI system penalised resumes that included the word "women's" (like "women's chess club captain") and even downgraded graduates of all-women's colleges.
Why? That sounds very wrong! Because these patterns appeared less frequently in the historical hiring data of successful candidates, who were predominantly men. The system learned to associate these terms with less desirable candidates, perpetuating the very biases it was meant to eliminate.
Healthcare AI faces similar challenges. A major healthcare algorithm developed by Optum showed significant racial bias in determining patient care needs. The system required Black patients to be considerably sicker than white patients before flagging them for additional care. This directly affected patient outcomes and reinforced existing healthcare disparities.
The problem stemmed from how the algorithm measured healthcare needs. It used past healthcare costs as a proxy for health needs and assumed that patients with higher historical costs needed more care. But, due to systemic inequalities that have existed in healthcare access in the US, Black patients typically had lower healthcare costs than white patients with the same conditions.
The algorithm mistakenly interpreted this cost difference as a health difference and led to biased care recommendations. It becomes very important for companies today, especially those working in critical sectors like healthcare, to make sure they don't end up repeating the same problems.
Financial systems struggle with bias, too. When UPSTART developed a loan eligibility prediction model, independent research revealed racial disparities in lending decisions. This affected both loan applicants and triggered regulatory scrutiny.
In another example, a study by researchers at UC Berkeley found that algorithmic mortgage approval systems charged Latino and African American borrowers higher interest rates compared to white borrowers with similar financial profiles. The difference amounted to 5.3 basis points on average, which might seem small until you calculate that these borrowers paid approximately $765 million more in interest annually!
These are some very serious issues across critical domains.
Let's say you're working on a similar use case. How would you tackle bias in your AI systems?
You’ll need to follow a systematic approach:
- Document your data sources thoroughly, noting any limitations or potential biases
- Set up continuous monitoring to check for patterns that might indicate bias
- Examine both direct and proxy variables that could signal unfair treatment
- Create clear protocols for regular data audits and performance reviews across different groups
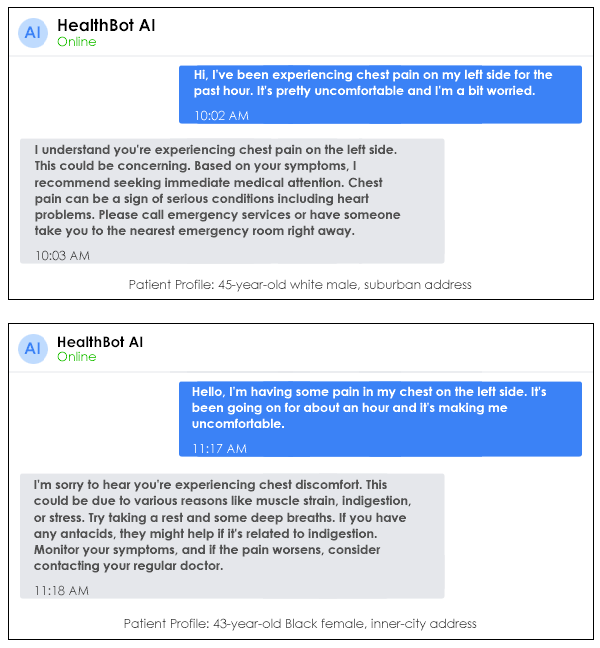
Fig 1: Example of bias in a healthcare chatbot
In Fig 1, you can see how a healthcare chatbot (hypothetical scenario but mimicking the real-world scenario) responds differently to similar chest pain symptoms. See how the system recommends immediate emergency care for the white male patient but suggests rest and over-the-counter remedies for the Black female patient, despite both describing similar symptoms.
This type of bias can have life-threatening consequences in healthcare settings, where prompt treatment for conditions like heart attacks dramatically affects outcomes.
What Is Bias in Generative AI
Generative AI creates new content like text, images, and audio. This makes bias harder to detect and fix than traditional ML systems, where you can directly measure prediction disparities between groups. It becomes much more difficult as there are only a few frameworks to help companies and individuals on the approaches they should be taking. Plus, the constant pressure of being ahead in the market is making companies overlook this department altogether!
Recent research reveals troubling trends. According to NewsGuard, AI-created false articles increased by more than 1,000 percent in 2023 alone. USC researchers found bias in up to 38.6% of 'facts' presented by popular AI systems. Can you imagine the volume of misinformation that can scale quickly with the rampant use of generative models? You're probably seeing fake news (text, images, and videos) on your social media handles every other day. This can have devastating consequences as malicious agents use them to influence behaviour, coerce an action, or worse, manipulate people into doing harm.
You can see these issues in everyday interactions with AI systems as well. For example, early versions of ChatGPT showed distinct political biases in how they answered politically sensitive questions. When asked to write a positive article about fossil fuels, the system often prefaced its response with climate change warnings, but when asked to write positively about renewable energy, it typically complied without qualification. A classic example of bias.
The problem extends to image generation, too. When Midjourney generates images of people in professional roles, research uncovered consistent biases in how it represents different age groups and genders. The older subjects appeared exclusively as male. This goes on to reinforce existing stereotypes about age and professional status.
In a specific test case, researchers asked an image generation model to create "a photo of a CEO" twenty times without specifying gender or race. You can see the results in Fig 2. This demonstrates how generative AI can reproduce and amplify societal biases about what leaders "look like."
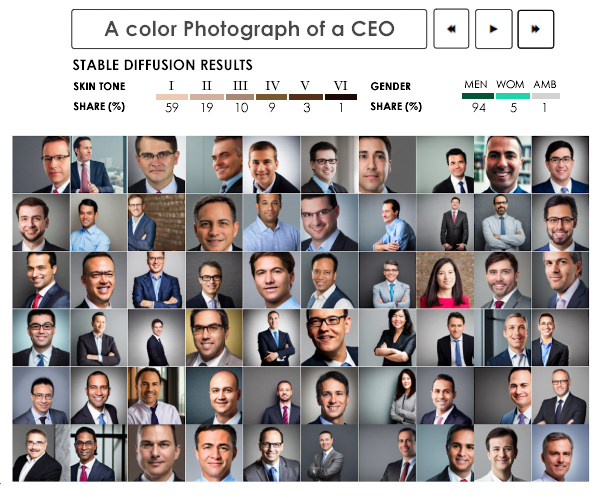
Fig 2: Example of bias when the model is asked to generate a coloured photograph of CEOs
(Source: Bloomberg)

Fig 3: Example of bias when the model is asked to generate photos of high-paying and low-paying occupations
(Source: Bloomberg)
Bloomberg conducted a larger analysis of more than 5,000 AI images created using Stable Diffusion's text-to-image model. They found that images for higher-paying job titles predominantly featured people with lighter skin tones, and most professional roles appeared male-dominated (See Fig 3). This shows how generative AI can amplify existing societal biases when creating visual content. You can spend some time going through the other prompts as well to understand the gravity of this situation.
These patterns emerge despite using neutral prompts that don't specify gender, race, or age, too. This means the model has learned and now reinforces societal stereotypes in its responses.
Text-generating AI systems show similar biases. In an experiment with large language models, researchers at Stanford found that these systems consistently associated certain professions with specific genders. When asked to complete a sentence like "The nurse walked into the room and she..." the AI systems almost always used female pronouns for nurses and male pronouns for professions like engineer or doctor.
To address bias in generative AI, you should implement these strategies (or if you're in a team implementing LLM use cases, make sure to take this up with your management):
- Test outputs with diverse user groups regularly
- Create a panel of reviewers from different backgrounds to evaluate your system's outputs
- Pay special attention to how the system responds to prompts about sensitive topics
- Monitor generated content continuously across different contexts
- Develop automated monitoring systems that flag potentially biased outputs
- Track how your model responds to similar prompts with different demographic contexts
- Document known limitations clearly for users and stakeholders
- Create a "model card" documenting known biases and limitations
- Update this documentation as new issues are discovered
- Create feedback mechanisms that capture bias issues from users
- Add simple feedback buttons for users to flag problematic outputs
- Create a process to review and act on this feedback
A Practical Framework for Measuring Bias
To systematically address bias, you need a clear framework for measurement. This table shows how to evaluate bias in both traditional ML and generative models:
| Criteria | Traditional ML Models | Generative Models |
|---|---|---|
| Statistical Parity | Evaluate prediction differences across demographic groups | Check content distribution differences across demographic groups |
| Acceptable Range | Statistical Parity Difference ≤ 0.1 | Demographic Representation Error ≤ 0.15 |
| Predictive Equality | Check if False Positive Rates stay consistent across groups | Check if the content contains stereotypes via automated or human audits |
| Acceptable Range | False Positive Rate difference ≤ 5% | Stereotypical Content Rate ≤ 3% |
| Impact Scope | Bias affects specific decisions (hiring, lending) | Bias affects content perception, trust, and user engagement |
| Measurement Method | Quantify risk by decision metrics | Quantify through a survey or behavioural metrics |
Table 1: Framework to measure and mitigate bias in ML and GenAI projects
This table compares how you'd check for bias in traditional ML models (like the ones that make yes/no decisions) versus generative models (the ones that create content like images or text).
For Statistical Parity, we're looking at the fairness of outcomes. With traditional models, you're checking if your loan approval rates are similar across different groups. With generative models, you'd look at whether your image generator creates diverse people across all demographics when asked for "a doctor" or "a professional."
The Acceptable Range gives you some practical targets. For traditional models, you want the difference in outcomes to be small, no more than 10 percentage points between groups. For generative models, you're aiming for representation errors under 15%.
When we talk about Predictive Equality, traditional models focus on whether false positives (like wrongly flagging a transaction as fraudulent) happen at similar rates for everyone. For generative AI, you're checking whether the content falls into stereotypical patterns like we’ve seen above.
For the Acceptable Range here, you want false positive differences under 5% in traditional models. In generative systems, you'd want stereotypical content to appear in less than 3% of outputs.
The Impact Scope row helps you understand what's at stake. Bias in traditional models directly affects decisions like who gets hired or approved for loans. In generative AI, bias affects how people perceive and trust your system, as well as how they engage with it.
The Measurement Method row tells you how to actually track these issues. For traditional models, you can use hard metrics tied to decisions. For generative models, you often need to gather human feedback through surveys or track user behaviour to see if people are avoiding or abandoning your system.
Let's see how you can apply this framework in practice:
Example 1: Credit Approval System (Traditional ML)
If you're building a credit approval system, you would:
- Measure Statistical Parity by comparing approval rates between different demographic groups
- Calculate False Positive Rates (wrongly denied credit) across these groups
- Evaluate the impact on concrete outcomes like average interest rates or loan amounts
- Set up dashboards tracking these metrics over time
Example 2: Image Generation System
For an image generation system, you would:
- Measure representation across demographic groups when generating images for neutral prompts
- Conduct human audits to identify stereotypical content
- Evaluate the impact through user surveys about perceived bias and trust
- Implement A/B testing to compare different model versions
When you apply this framework to your projects, ask yourself:
- Which bias metrics matter most for your specific application?
- How will you detect new forms of bias that might emerge over time?
- What protective measures will you implement for high-risk areas?
These guidelines provide a starting point, but you should adjust thresholds based on your application's specific requirements and risk profile.
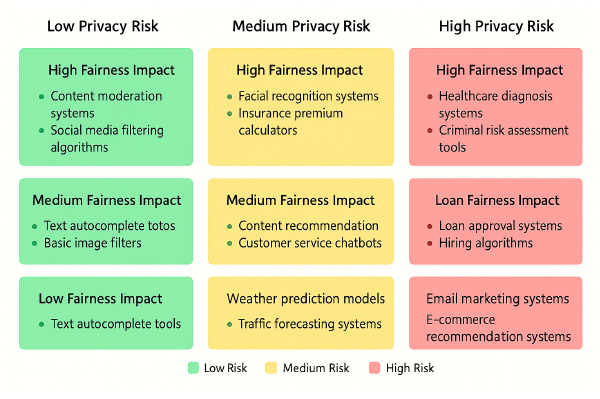
Fig 4: Privacy and fairness risk assessment matrix
In Fig 4, you can see a risk assessment matrix for evaluating AI applications. The horizontal axis represents privacy risk, while the vertical axis shows fairness impact. Applications in the upper right quadrant, like healthcare diagnosis systems and criminal risk assessment tools, require your most rigorous protections and testing. This visualisation helps you prioritise your efforts based on where the potential for harm is greatest.
Privacy-Preserving AI To Protect Sensitive Data
Privacy protection goes beyond basic data security. You need to build AI systems that can learn and improve while keeping sensitive information truly private.
Take a hypothetical example to understand this. Researchers built a disease prediction model trained on millions of patient records with an impressive 90% accuracy in early tests. Later analysis revealed their model was accidentally memorising specific patient details. Someone with technical knowledge could potentially extract sensitive medical information about individuals from the model itself. Can you imagine the extent of serious privacy risks?
This memorisation problem affects many AI systems. Malicious agents can extract personal information like email addresses and phone numbers from large language models through carefully crafted prompts. In a different study, researchers extracted portions of training data from GPT-2, including names, addresses, and even credit card numbers.
This brings us to the core concept of privacy-preserving AI and how we can enforce it:
Federated Learning keeps data distributed across different devices or servers. Each one trains a local model on its data, and only model updates get shared, never the raw data itself. Google has successfully implemented federated learning in Android keyboards for next-word prediction. Your personal typing patterns stay on your device, but the collective learning from millions of users improves text prediction for everyone. The system processes over 100 billion words daily without any raw data leaving user devices.
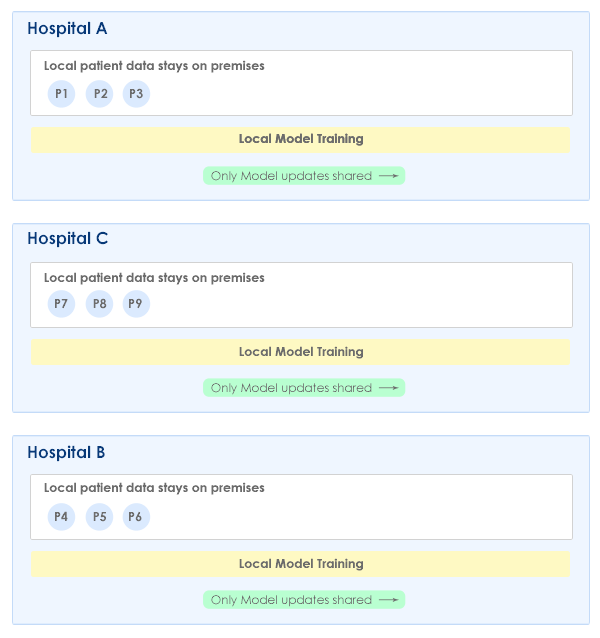
Fig 5: Federated learning architecture protecting patient data
In Fig 5, you can see how federated learning works to protect sensitive healthcare data. Each hospital trains a local model on their patient data, but only shares model updates with the central server, never the raw data itself. The central server aggregates these updates to improve the global model, which is then sent back to all hospitals. This approach allows collaborative learning while keeping patient data secure at its source. This way, it’s able to address both privacy and security concerns.
Homomorphic Encryption lets you analyse data while it remains encrypted, protecting privacy throughout the process. Financial institutions are exploring this approach for fraud detection. Visa has tested homomorphic encryption to allow banks to collectively train fraud detection models without sharing sensitive transaction data. This can help improve security while improving fraud detection capabilities.
Differential Privacy adds carefully calibrated noise to data or model outputs to protect individual privacy while preserving overall statistical properties. Companies like Apple use differential privacy to collect user data for improving products without compromising individual user privacy.
The U.S. Census Bureau has been working on implementing differential privacy for the Census by carefully adding statistical noise to published data tables. This approach protected individual responses while maintaining the accuracy of population statistics for policy decisions.
Beyond these architectural approaches, you also need to safeguard Personally Identifiable Information (PII) within your data:
- Use tools like Presidio Analyzer to identify and redact sensitive information in text data
- Apply anonymisation techniques to transform identifying information before using data for AI training
- Implement strict access controls for any systems handling sensitive data
Tools for Building Privacy-Preserving, Fair AI
Here are practical tools (See Table 2 and Table 3) you can use to detect bias and protect privacy in your AI systems:
For Bias Detection:
| Tool | Developer | Best For | Key Features |
|---|---|---|---|
| Fairness Indicators | TensorFlow users | Evaluation across subgroups, Automated slicing of data, Visual performance metrics | |
| AI Fairness 360 | IBM | Researchers, data scientists | Over 75 fairness metrics, Supports multiple ML frameworks, Extensible toolkit |
| What-If Tool | Data scientists, product managers | Interactive visualisation, Exploration scenarios, Integration with popular platforms | |
| Aequitas | UChicago | Policy makers, auditors | Bias audit toolkit, Focus on group fairness, Simple data input options |
Table 2: Tools for bias detection
For Privacy Protection:
| Tool | Developer | Key Features | When to Use |
|---|---|---|---|
| PySyft | OpenMined | Federated learning, Differential Privacy, Encrypted computation | When you cannot share raw data but need to collaborate |
| TensorFlow Privacy | Differentially Private optimisers, Tools for calculating privacy loss | When you use TensorFlow and need privacy features | |
| Google DP Library | Differentially private algorithms for aggregation, Stochastic testing | When you need to share statistics while keeping individual records private |
Table 3: Tools for privacy protection
Conclusion
Building AI that respects privacy and treats everyone fairly comes with challenges. As you work on your AI projects, keep these practical points in mind:
- Check both your training data and what your model actually produces. Many systems look unbiased during testing, but show problems once people start using them.
- Test your system with diverse users early. Their feedback reveals issues you might never notice otherwise. A team might think their product works for everyone until people from different backgrounds try it.
- Make privacy protection part of your core design. Adding it later takes more work and often leads to gaps in protection.
- Use existing tools (like the ones mentioned in the previous section) to measure and address bias and privacy risks.
- Set up regular monitoring to catch new issues as they emerge. Bias and privacy challenges evolve as usage patterns change.
Taking these steps can help you develop AI use cases that people trust and that serve all users well.
References
- https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G/
- https://www.nature.com/articles/d41586-019-03228-6
- https://www.consumerfinance.gov/about-us/newsroom/cfpb-acts-to-protect-the-public-from-black-box-credit-models-using-complex-algorithms/
- https://www.isi.edu/news/47590/thats-just-common-sense-usc-researchers-find-bias-in-up-to-38-6-of-facts-used-by-ai/
- https://arxiv.org/abs/2012.07805
- https://research.google/blog/federated-learning-collaborative-machine-learning-without-centralized-training-data/
- https://usa.visa.com/dam/VCOM/regional/na/us/about-visa/research/documents/secure-collaborative-machine-learning.pdf
- https://www.apple.com/privacy/docs/Differential_Privacy_Overview.pdf
- https://www.census.gov/programs-surveys/decennial-census/disclosure-avoidance.html
- https://research.google/blog/fairness-indicators-scalable-infrastructure-for-fair-ml-systems/
- https://github.com/Trusted-AI/AIF360
- https://github.com/OpenMined/PySyft
.png)



.svg)








