




You've spent months building the perfect machine learning model. Your accuracy metrics look fantastic, your validation results are solid, and you’re excited about deployment.
Then you realise: your model file is 2GB, takes 30 seconds to make a single prediction, and requires expensive GPU infrastructure just to run basic inference.
Say you need to serve thousands of predictions per minute, but your current setup can barely handle ten. The model that worked great in your development environment becomes a choke point when real users start interacting with it.
When working with ML and DL models, this is quite a familiar scenario, isn’t it?
The gap between a working model and a production-ready system often comes down to two critical factors: model efficiency and operational scalability.
In our previous explorations of data quality pipelines and bias detection frameworks, we focused on building robust foundations for AI systems. We'll now need to talk about the practical challenge of making these systems work efficiently at scale. This means compressing models without affecting performance and building MLOps pipelines that can handle production workloads.
Model compression reduces the size and computational requirements of your trained models, while scalable MLOps creates the infrastructure to deploy, monitor, and maintain these models across different environments. Together, they turn experimental models into systems that actually work for real users. Ready?
Why Model Compression Matters in Production
Consider a mobile app that needs to classify images in real-time. Your original model works well, but it weighs 500 MB. Most users won't download an app that large, and even if they do, the model drains their battery and consumes excessive data. You need the same accuracy in a package that's 50x smaller.

Fig 1: Model Performance vs Size Comparison
In Fig 1, you can see how different compression techniques affect model size and accuracy trade-offs. The original model provides baseline performance, while various compression approaches achieve balance points between efficiency and accuracy.
Financial institutions face similar constraints. A fraud detection model that takes 10 seconds to evaluate a transaction becomes useless when customers expect instant payment processing. In the same way, healthcare applications need models that work on edge devices in areas with limited connectivity.
Real-world results demonstrate the impact of these constraints. In 2019, researchers achieved 35x to 49x compression on ImageNet models like AlexNet and VGG-16 without accuracy loss. AlexNet's size dropped from 240MB to 6.9MB, while VGG-16 compressed from 552MB to 11.3 MB.
Model compression techniques address these real-world constraints through several approaches:
Approach 1: Quantisation
Quantisation reduces the precision of model weights and activations. Instead of using 32-bit floating-point numbers, you can often achieve similar results with 8-bit integers. Think of this as measuring distances with a ruler with fewer markings. Instead of measuring to the nearest millimetre, you measure to the nearest centimetre. You lose some precision, but for most practical purposes, the measurement is still useful enough to get the job done. Look at Fig 2 to understand quantisation in detail.
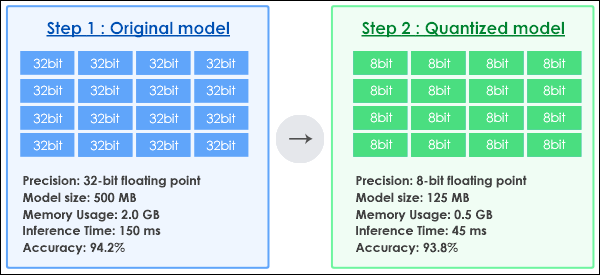
Fig 2: How quantisation works
Approach 2: Pruning
Pruning removes less important connections between neurons. Think of this as trimming unnecessary branches from a tree while keeping the main structure intact. Structured pruning removes entire neurons or layers, while unstructured pruning eliminates individual connections. See Fig 3.
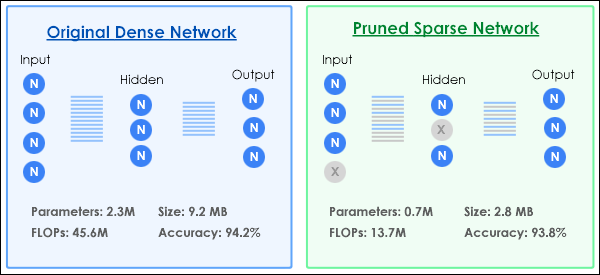
Fig 3: How pruning works
Approach 3: Knowledge distillation
Knowledge Distillation trains a smaller "student" model to mimic the behaviour of a larger "teacher" model. The student learns to produce similar outputs without needing the same complex internal structure. See Fig 4.
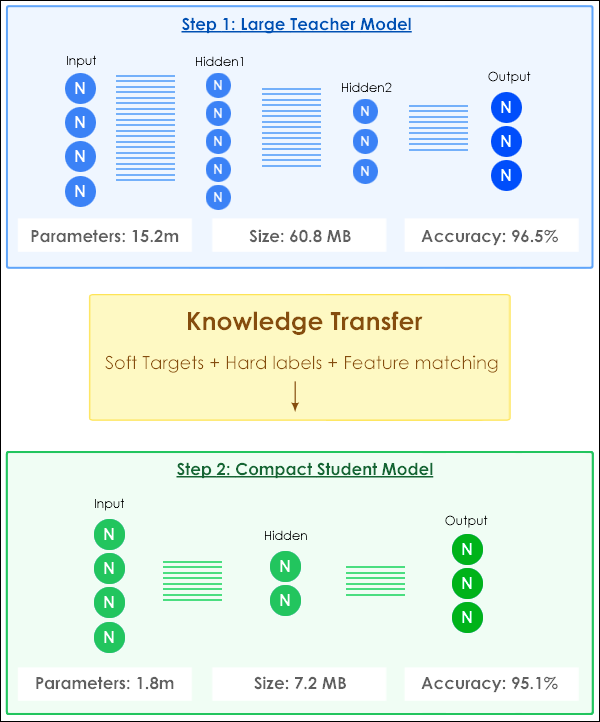
Fig 4: How knowledge distillation works
The Challenge of Scalable MLOps
Building a single model is one thing. Operating dozens of models across different environments, each with varying traffic patterns and performance requirements, is entirely different.
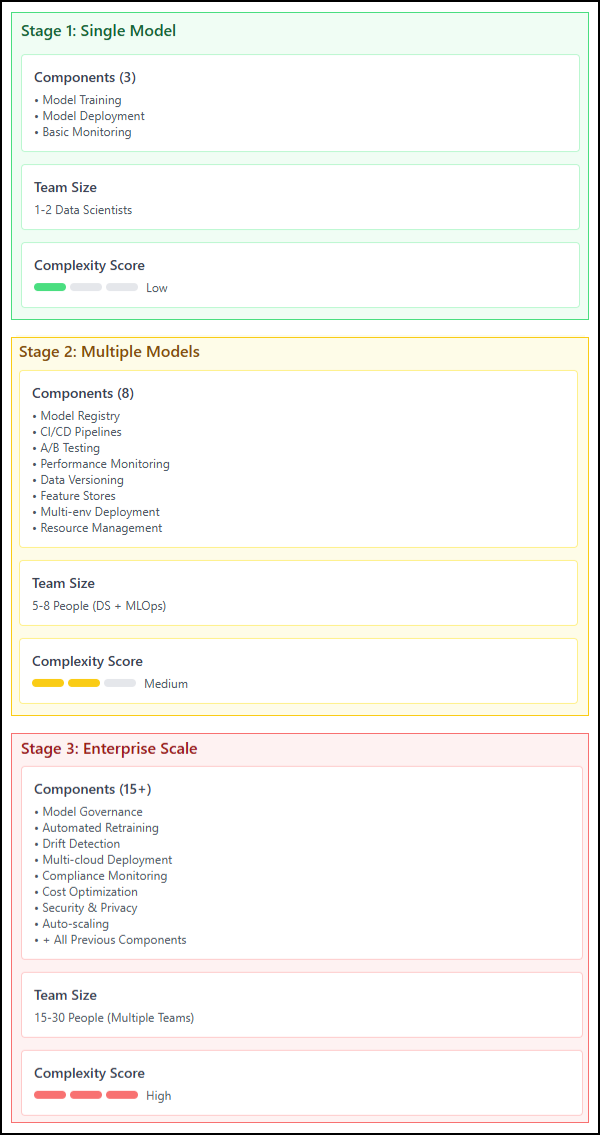
Fig 5: The complexity growth of MLOps pipelines
Fig 5 shows how MLOps complexity grows as you add more models, environments, and team members. What starts as a simple deployment quickly becomes a complex system requiring careful arrangement.
You need systems that can automatically deploy model updates, monitor performance degradation, and scale resources based on demand. Traditional software deployment practices don't work directly for machine learning because models have unique characteristics like data drift, concept drift, and performance degradation over time.
Consider an e-commerce recommendation system. During normal traffic, your model handles 1,000 requests per minute comfortably. During Black Friday, traffic spikes to 50,000 requests per minute. Your infrastructure needs to scale automatically while maintaining response times under 100 milliseconds.
Google's experience with MLOps demonstrates these challenges. Their production ML systems require continuous integration, delivery, and training pipelines that differ significantly from traditional software deployment.
The challenge also goes beyond handling traffic spikes. You need to monitor model accuracy in production, detect when retraining is necessary, and coordinate updates across multiple services without downtime.
Practical Model Compression Strategies
Let's walk through specific compression techniques you can implement:
Post-Training Quantisation works with your existing trained models. You can apply this technique without retraining, making it the simplest starting point. Research indicates most models maintain 90-95% accuracy when quantised from 32-bit to 8-bit precision.
Progressive Compression combines multiple techniques sequentially. You might start with pruning to remove unnecessary parameters, then apply quantisation to reduce precision, and finally use knowledge distillation to create an even more efficient model.
The key is measuring the impact of each technique on your specific use case. A 10% accuracy drop might be acceptable for a recommendation system, but unacceptable for medical diagnosis.
Structured Pruning removes entire neurons, making the resulting models naturally smaller and faster. Unlike unstructured pruning, which creates sparse models that require special hardware to benefit from, structured pruning works on standard hardware.
A practical example comes from mobile deployment research. When researchers applied pruning to AlexNet, the resulting network was 9 times smaller and 3 times faster than the original network without any reduction in accuracy.
Building Scalable MLOps Infrastructure
Effective MLOps infrastructure handles the entire model lifecycle, from development to retirement. This includes version control for models, automated testing, deployment pipelines, and monitoring systems.
Model Versioning tracks not just the model files but also the training data, hyperparameters, and code used to create each version. When a model performs poorly in production, you need to understand exactly what changed between versions.
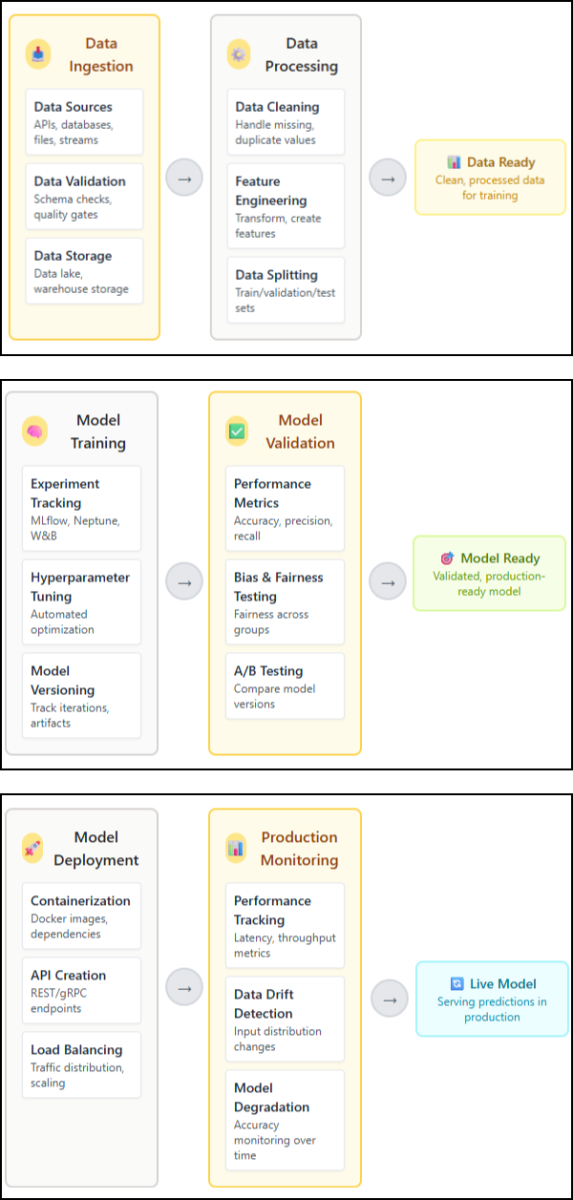
Fig 6: Scalable infrastructure for MLOps
In Fig 6 shows a complete MLOps pipeline from data ingestion through model retirement. Each stage includes automated testing and quality gates to prevent problematic models from reaching production.
Automated Testing for ML models goes beyond traditional software testing. You need tests for data quality, model performance, bias detection, and resource usage. These tests run automatically whenever someone proposes a model update.
According to Gartner's research, productivity gains from AI will be recognised as a primary economic indicator by 2027, making MLOps implementation critical for competitive advantage.
Deployment Strategies for ML models require special consideration. Blue-green deployments work well for models that don't maintain state, while canary deployments help you test new models on a small portion of traffic before full rollout.
Monitoring Systems track both technical metrics (latency, throughput, error rates) and business metrics (accuracy, bias, fairness). This is important because model performance can degrade silently over time due to scenarios like data drift.
Implementing Compression and MLOps Together
The most effective approach combines model compression with robust MLOps practices. Your compression pipeline becomes part of your overall MLOps workflow, automatically optimising models for different deployment targets.

Fig 7: Integrated compression and deployment pipeline
Fig 7 shows how compression steps integrate into the MLOps pipeline. Different deployment targets (mobile, edge, cloud) receive appropriately optimised models automatically.
Environment-specific optimisation creates different model variants for various deployment scenarios. Your mobile app gets a heavily compressed model, while your cloud API uses a larger model for maximum accuracy. The same MLOps pipeline manages all variants.
Automated Compression runs compression techniques as part of your CI/CD pipeline. When accuracy drops below acceptable thresholds, the system can automatically adjust compression parameters or flag the model for manual review.
Performance Monitoring tracks how compression affects real-world performance. You might discover that a 50% size reduction has no impact on user satisfaction, enabling more aggressive optimisation.
How Do You Measure Your Success in Production
Success metrics for compressed models and MLOps systems extend beyond traditional accuracy measurements. You need to track operational metrics that reflect real-world constraints.
Latency Measurements should cover the entire prediction pipeline, not just model inference time. Data preprocessing, feature extraction, and result formatting contribute to user-perceived performance.
Resource Utilisation tracking helps optimise costs and capacity planning. Models that use 90% less memory enable higher throughput on the same hardware, directly impacting your infrastructure costs.
User Experience Metrics like app launch time, battery usage, and data consumption often matter more than model accuracy differences of a few percentage points.
Research from MLOps practitioners shows that organisations implementing comprehensive model compression see significant operational improvements across these metrics.
Popular Tools for Model Compression and MLOps
Several tools can help you implement these approaches:
TensorFlow Lite and PyTorch Mobile provide compression techniques specifically designed for mobile and edge deployment. They include quantisation, pruning, and optimisation tools integrated with the framework.
ONNX Runtime offers cross-platform model optimisation and deployment capabilities. It supports models from multiple frameworks and provides automatic optimisation for different hardware targets.
MLflow provides experiment tracking, model versioning, and deployment management. It integrates well with popular ML frameworks and cloud platforms.
Kubeflow orchestrates ML workflows on Kubernetes, providing scalable training and deployment infrastructure. It includes components for model serving, monitoring, and resource management.
Weights & Biases offers experiment tracking, model management, and collaboration tools. It provides detailed logging and visualisation capabilities for both training and production monitoring.
What’s the Way Forward
Model compression and scalable MLOps transform AI systems from research prototypes into production-ready solutions. The techniques we've explored help you build systems that work efficiently at scale while maintaining the performance your users expect.
Start with post-training quantisation to get immediate size reductions without retraining. Set up basic monitoring to understand your current performance baseline. Then, gradually add more sophisticated compression techniques and MLOps capabilities as your systems mature.
Your goal should be to build AI systems that work reliably for real users in real environments. This means balancing model performance with operational constraints and building infrastructure that can adapt as your needs change.
References
- https://arxiv.org/abs/1510.00149
- https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
- https://link.springer.com/article/10.1007/s10489-024-05747-w
- https://xailient.com/blog/4-popular-model-compression-techniques-explained/
- https://www.gartner.com/en/articles/gartner-s-top-strategic-predictions-for-2024-and-beyond
- https://www.frontiersin.org/journals/robotics-and-ai/articles/10.3389/frobt.2025.1518965/full
- https://ai.google.dev/edge/litert
- https://onnxruntime.ai/
- https://mlflow.org/
- https://www.kubeflow.org/
- https://wandb.ai/site/
.png)



.svg)








